
No tienes permitido ver los links.
Registrarse o Entrar a mi cuenta
Como se ha dicho en la entrada anterior, el funcionamiento interno de una red inalámbrica difiere un poco de las redes cableadas convencionales, ya que las redes inalámbricas añaden un nivel de complejidad adicional que se encuentra directamente relacionado a factores físicos del canal de comunicación (aire).
Hasta este punto se han introducido 3 conceptos importantes relacionados con las redes inalámbricas que son, los canales, los rangos de frecuencias y las bandas. En esta ocasión se intentará explicar cuales son los tipos y los subtipos que paquetes que existen en una red inalámbrica y que es necesario conocer con el fin de entender la información que estos suministran cuando son capturados por herramientas como wireshark. Por otro lado también se introduce el concepto de "beacon frames" que es vital para comprender como los routers inalámbricos envían señales a los clientes cercanos para informar sobre su presencia.
En las redes cableadas típicamente se componen por "Internet Frames" que están compuestos por una serie de campos que incluyen el protocolo utilizado (TCP/UPD/ICMP) y demás elementos que comprenden la capa de aplicación (ver modelo OSI sobre topología de red), en el mundo de las redes inalámbricas ocurre algo similar y existen diferentes tipos de paquetes WLAN, que se clasifican en 3 categorías principales que son:
Cada uno de estos tipos de paquetes a su vez contienen otros subtipos de paquetes, conocer estos tipos y subtipos permitirá realizar un análisis de paquetes que viajan en el aire y las implicaciones de seguridad que estos llevan consigo. Para ver en mayor detalle los subtipos de cada una de las categorías anteriormente descritas se recomienda visitar este sitio: No tienes permitido ver los links. Registrarse o Entrar a mi cuenta
Allí se incluye una tabla con cada uno de los tipos y sus correspondientes subtipos de paquetes, así como también se explica cual es su funcionamiento.
Por otro lado, se encuentran los access points que son los dispositivos que brindan acceso a la red inalámbrica, dichos dispositivos tienen asignado un SSID que le permite identificarse ante posibles usuarios que se encuentren en las cercanías, el SSID es en realidad solo un "nick" que indica el nombre de la red a la que un cliente determinado puede unirse, normalmente cuando una tarjeta de red encuentra un router cercano que advierte sobre su presencia, el usuario final solamente ve el SSID y la intensidad de la frecuencia que emite dicho router, lo que normalmente indica la cercanía, dado que las redes inalámbricas se ven enfrentadas a diferentes problemas relacionados con el medio y los obstáculos que se presentan en el mismo, (objetos, paredes, etc.) la intensidad de la frecuencia de un router se puede ver disminuida por factores físicos tales como la reflexión y la atenuación de la señal, lo que al final se ve directamente reflejado en la calidad de la conexión e inclusive la perdida de datos en el proceso de transmisión, sin embargo esto se verá con mayor detenimiento en próximas entradas.
Por otro lado, el mecanismo que utilizan los routers para anunciar su presencia a clientes que podrían estar interesados en conectarse es por medio del envío "abierto" o envío broadcast de lo que se conoce como "Beacon Frames", estos frames contienen información relacionada con el dispositivo que se encuentra disponible y da algunas pautas para realizar la conexión con el mismo, entre la información incluida en dichos frames se incluye el mecanismo de autenticación en el caso de que la red se encuentre protegida por contraseña o si por el contrario es una red sin ningún tipo de restricciones de acceso. Estos Beacon frames se transmiten con una periodicidad fija que permite a los clientes potenciales estar al tanto de posibles cambios que ocurren en el dispositivo.
En la entrada anterior se ha realizado una corta introducción sobre el uso de aircrack-ng (herramienta recomendada para realizar ataques sobre redes inalámbricas) y como es posible establecer la tarjeta de red inalámbrica en modo monitor (el equivalente del modo promiscuo en redes cableadas), esto será útil para capturar Beacon Frames
Posteriormente es posible utilizar airodump-ng para capturar todos estos Bacon Frames de forma cíclica recorriendo los canales, sin embargo para conocer en detalle los campos incluidos en dichos frames, se puede ejecutar wireshark, seleccionar la interfaz en modo monitor creada anteriormente por airmon-ng y comenzar la captura de paquetes (no es necesario esperar más de un par de segundos antes de recibir un listado de dichos paquetes, así que se puede detener la captura después de unos pocos segundos). En la columna de "Destination" se podrá apreciar que algunos paquetes tienen el valor de "Broadcast" además de que en la columna de "Info" la descripción inicial del paquete contendrá algo como "Beacon Frame, SN=XXXX, FN=X, FLAGS=XXX"
Ahora bien, es importante anotar que no solamente los Access Points (AP) pueden transmitir Bacon Frames, de hecho, cualquiera puede hacerlo sin ser necesariamente un AP, es por este motivo que es importante también ver algunas de las propiedades que se incluyen en los paquetes capturados, principalmente aquellas propiedades que se encuentran ubicadas en "Fixed Parameters" y "Tagged Parameters", por ejemplo en las siguientes imágenes se enseña en primer lugar el valor del parámetro "Capability Information" que indica, entre otras si el dispositivo que ha enviado el frame es un AP y por otro lado se encuentra el valor del parámetro "SSID parameter set" que indica el identificador del AP.
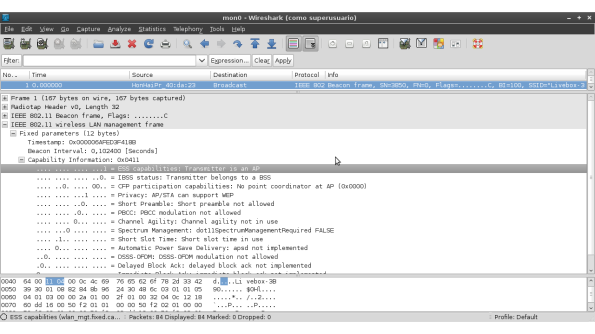

En la imagen anterior, (Tagged parameters) se incluye otra información interesante que también es útil, como por ejemplo las frecuencias soportadas, el canal de ejecución actual del AP, mecanismo de autenticación, etc.
Ahora bien, todos los dispositivos inalámbricos tienen la capacidad de anunciar su presencia a otros dispositivos que se encuentran cerca, es decir, todos los dispositivos tienen (teóricamente) la capacidad de enviar Beacon Frames, evidentemente la tarjeta de red inalámbrica y el driver utilizado para controlarla deben soportar esta característica para poder ser empleada, esto a efectos prácticos significa que un atacante podría inyectar sus propios Beacon Frames haciéndose pasar por un AP, evidentemente se requiere una herramienta que permita realizar este tipo de actividades, aircrack-ng puede ser útil para este fin, no obstante en esta ocasión se mencionará otra herramienta que permitirá realizar esta tarea de una forma sencilla y efectiva, se trata de MDK3, a continuación se explica como es el procedimiento de instalación y uso.
Se trata de una herramienta que permite realizar operaciones varias sobre paquetes y redes inalámbricas, algunas de las características soportadas son, Prueba de redes (para verificar que pueden escuchar los beacon frames del atacante), Fuerza Bruta para filtros MAC, Fuerza Bruta para SSID ocultos, Inyección de paquetes de Deautenticacion y Desasociacion, FakeAP, etc. La instalación es muy simple, solo es necesario descargar la herramienta desde No tienes permitido ver los links. Registrarse o Entrar a mi cuenta y posteriormente ejecutar el comando "make && make install" desde linea de comandos para realizar la instalación de la herramienta.
Cuando se ejecuta el comando mdk3 sin ningún argumento, se enseñan todos los mecanismos empleados por mdk3 y cada una de estas técnicas tienen un conjunto de opciones para personalizar su ejecución, en este caso concreto interesa utilizar el modo de prueba "Beacon Flood Mode" que corresponde a la opción "b", para conocer las opciones de este modo de prueba
Ahora, la ejecución del comando con la opción "b" podría incluir un SSID "falso" que identifique cada uno de los Beacon Frames enviados por broadcast a los clientes cercanos, para ello se ejecuta el siguiente comando
Como puede verse, se ejecuta de forma repetida el envío de Beacon Frames sobre distintos canales (aquí "mon0" corresponde a la interfaz en modo monitor), posteriormente cualquier cliente reconocerá dichos Beacon Frames y posiblemente los identificará como emisiones provenientes de un AP que se encuentra cerca.
Siguiendo los mismos pasos indicados anteriormente, se intenta realizar una captura de paquetes utilizando wireshark, se podrá ver que algunos de los paquetes capturados tienen en la columna "Info" un valor similar al siguiente "Beacon frame, SN=0, FN=0, Flags=........, BI=100, SSID="REMEMBER" posteriormente si se consultan los campos "Capability Information" y "SSID parameter set" (tal como se ha enseñado en las imágenes que se encuentran en párrafos anteriores) el paquete capturado tiene la apariencia de un AP.
Cuando un cliente se autentica y se asocia a un AP (realiza una conexión completa) se llevan a cabo una serie de pasos y existe un intercambio de paquetes entre ambas partes que les permiten negociar una conexión entre ambos e intercambiar, posteriormente paquetes de datos.
El paso inicial lo toma el cliente y consiste en el envío de paquetes "Probe Request" que son del tipo Broadcast a cualquier AP que se encuentre cerca, la finalidad de estos paquetes es la de localizar y obtener los SSID de los AP disponibles, el cliente se mantendrá enviando este tipo de frames con la finalidad de obtener respuestas de los AP disponibles, estos a su vez responden con paquetes del tipo "Probe Response" que contienen información sobre el AP, posteriormente el cliente inicia todo el proceso de autenticación y asociación con el AP. Todo el proceso se resume en el siguiente intercambio de paquetes:
"Probe Request" → "Probe Response" → "Authentication Request" → "Authentication Response" → "Association Request" → "Association Response" → "NULL Function (No Data)" → "Disassociate".
El primer paquete "Probe Request" que el cliente envía a todos los AP cercanos, es una petición del tipo "Soy un cliente nuevo y busco AP's en el área, enviadme vuestros SSID" el siguiente paquete que es el "Probe Response" es el de respuesta de dicha petición, donde cada uno de los AP responde con su SSID (excepto aquellos que tienen SSID oculto, se verá más adelante en próximas entradas) además de esto, también incluye información relacionada con el mecanismo de autenticación y parámetros de seguridad existentes en el AP antes de comenzar la interacción con este. Posteriormente el cliente envía un paquete de "Probe Request" a un SSID concreto (el primero ha sido broadcast a todos los AP disponibles) e inicia el proceso de autenticación sobre dicho AP que ha respondido a la petición, dependiendo del mecanismo de autenticación implementado en dicho AP, estos paquetes podrán ser trazables o no, en cualquier caso, el siguiente paso es el intercambio de una serie de paquetes del tipo "Authentication" (Request por parte del cliente y Response por parte del AP) que intentan determinar si el cliente tiene autorización para asociarse con el AP, una vez este proceso ha concluido correctamente, el cliente envía una petición "Association Request" al AP para que este establezca la conexión con el cliente y le asigne una dirección IP valida (típicamente por medio de un servidor DHCP), el AP envía un paquete "Association Response" el cual contiene la respuesta exitosa o fallida de la asociación del cliente con el AP, esta respuesta se encuentra contenida en los "Fixed Parameters" con los campos "Status Code" y "Association ID" cuando el procedimiento de asociación finaliza correctamente estos campos tienen el valor de "Successful 0×0000" y "0×0001" respectivamente. Ahora con un cliente conectado con el AP, comienza el proceso de intercambio de paquetes de datos entre el cliente y el AP, por ejemplo, cuando un cliente solicita una página en internet o intenta intercambiar paquetes con otra máquina conectada en el segmento de red. Finalmente, el proceso de Des-asociación, es iniciado por el cliente y se lleva a cabo cuando este desea finalizar la interacción con el AP, en este caso el AP "des-asocia" el cliente terminando la conexión existente.
El proceso completo se entiende mejor con un ejemplo practico, para ello se pueden seguir los siguientes pasos
1.Iniciar un AP sin establecer mecanismo de autenticación utilizando airbase-ng
3.Iniciar wireshark e iniciar una captura activa de paquetes utilizando la interfaz monitora "mon0"
4.Ahora, para que la captura sea "limpia" se debe establecer un filtro en el que solamente se enseñen los frames cuya dirección corresponda al AP "WLAN_OPEN" y ademas es necesario filtrar también los Beacon Frames, con el fin de solamente recibir aquellos frames relacionados con el proceso de asociación de un cliente con un AP. Esto se hace como se enseña en las imágenes.

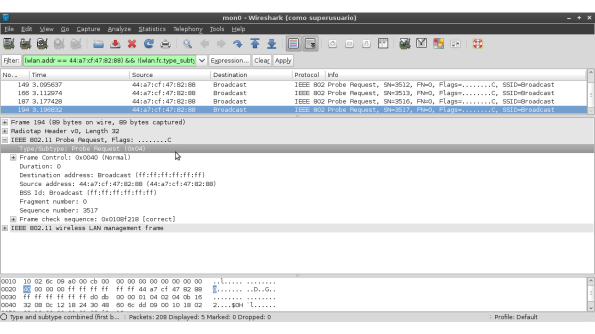
Como puede apreciarse el filtro resultante es el siguiente
De esta forma, desde wireshark solamente se listarán registros de frames correspondientes al AP "WLAN_OPEN" y no se listarán sus Beacon Frames, solamente frames relacionados con la conexiones de otros clientes. Ahora cuando un cliente intenté realizar una conexión con el AP (Que no tiene ningún mecanismo de autenticación) se comenzará la serie de intercambio de paquetes indicada anteriormente, todos estos se pueden analizar desde wireshark
Como conclusión final de esta entrada, es importante anotar que realizar spoofing de Beacon frames es una tarea sencilla, la razón de esto es por que no existe cifrado de datos, todo viaja en texto claro y por otro lado no existe un mecanismo de protección disponible contra este tipo de ataques de reconocimiento, aunque por si mismos no son demasiado dañinos, suministran información a un posible atacante de los AP que se encuentran en "su vecindad".
LOG DE MODERACION: Siempre deben ser citadas las fuentes.
No tienes permitido ver los links. Registrarse o Entrar a mi cuenta
Como se ha dicho en la entrada anterior, el funcionamiento interno de una red inalámbrica difiere un poco de las redes cableadas convencionales, ya que las redes inalámbricas añaden un nivel de complejidad adicional que se encuentra directamente relacionado a factores físicos del canal de comunicación (aire).
Hasta este punto se han introducido 3 conceptos importantes relacionados con las redes inalámbricas que son, los canales, los rangos de frecuencias y las bandas. En esta ocasión se intentará explicar cuales son los tipos y los subtipos que paquetes que existen en una red inalámbrica y que es necesario conocer con el fin de entender la información que estos suministran cuando son capturados por herramientas como wireshark. Por otro lado también se introduce el concepto de "beacon frames" que es vital para comprender como los routers inalámbricos envían señales a los clientes cercanos para informar sobre su presencia.
TIPOS DE PAQUETES Y SUBPAQUETES EN REDES INALAMBRICAS
En las redes cableadas típicamente se componen por "Internet Frames" que están compuestos por una serie de campos que incluyen el protocolo utilizado (TCP/UPD/ICMP) y demás elementos que comprenden la capa de aplicación (ver modelo OSI sobre topología de red), en el mundo de las redes inalámbricas ocurre algo similar y existen diferentes tipos de paquetes WLAN, que se clasifican en 3 categorías principales que son:
- Management
- Control
- Data
Cada uno de estos tipos de paquetes a su vez contienen otros subtipos de paquetes, conocer estos tipos y subtipos permitirá realizar un análisis de paquetes que viajan en el aire y las implicaciones de seguridad que estos llevan consigo. Para ver en mayor detalle los subtipos de cada una de las categorías anteriormente descritas se recomienda visitar este sitio: No tienes permitido ver los links. Registrarse o Entrar a mi cuenta
Allí se incluye una tabla con cada uno de los tipos y sus correspondientes subtipos de paquetes, así como también se explica cual es su funcionamiento.
FUNCIONAMIENTO DE ACCESS POINTS INALAMBRICOS
Por otro lado, se encuentran los access points que son los dispositivos que brindan acceso a la red inalámbrica, dichos dispositivos tienen asignado un SSID que le permite identificarse ante posibles usuarios que se encuentren en las cercanías, el SSID es en realidad solo un "nick" que indica el nombre de la red a la que un cliente determinado puede unirse, normalmente cuando una tarjeta de red encuentra un router cercano que advierte sobre su presencia, el usuario final solamente ve el SSID y la intensidad de la frecuencia que emite dicho router, lo que normalmente indica la cercanía, dado que las redes inalámbricas se ven enfrentadas a diferentes problemas relacionados con el medio y los obstáculos que se presentan en el mismo, (objetos, paredes, etc.) la intensidad de la frecuencia de un router se puede ver disminuida por factores físicos tales como la reflexión y la atenuación de la señal, lo que al final se ve directamente reflejado en la calidad de la conexión e inclusive la perdida de datos en el proceso de transmisión, sin embargo esto se verá con mayor detenimiento en próximas entradas.
Por otro lado, el mecanismo que utilizan los routers para anunciar su presencia a clientes que podrían estar interesados en conectarse es por medio del envío "abierto" o envío broadcast de lo que se conoce como "Beacon Frames", estos frames contienen información relacionada con el dispositivo que se encuentra disponible y da algunas pautas para realizar la conexión con el mismo, entre la información incluida en dichos frames se incluye el mecanismo de autenticación en el caso de que la red se encuentre protegida por contraseña o si por el contrario es una red sin ningún tipo de restricciones de acceso. Estos Beacon frames se transmiten con una periodicidad fija que permite a los clientes potenciales estar al tanto de posibles cambios que ocurren en el dispositivo.
En la entrada anterior se ha realizado una corta introducción sobre el uso de aircrack-ng (herramienta recomendada para realizar ataques sobre redes inalámbricas) y como es posible establecer la tarjeta de red inalámbrica en modo monitor (el equivalente del modo promiscuo en redes cableadas), esto será útil para capturar Beacon Frames
Citar>airmon-ng start wlan0
Posteriormente es posible utilizar airodump-ng para capturar todos estos Bacon Frames de forma cíclica recorriendo los canales, sin embargo para conocer en detalle los campos incluidos en dichos frames, se puede ejecutar wireshark, seleccionar la interfaz en modo monitor creada anteriormente por airmon-ng y comenzar la captura de paquetes (no es necesario esperar más de un par de segundos antes de recibir un listado de dichos paquetes, así que se puede detener la captura después de unos pocos segundos). En la columna de "Destination" se podrá apreciar que algunos paquetes tienen el valor de "Broadcast" además de que en la columna de "Info" la descripción inicial del paquete contendrá algo como "Beacon Frame, SN=XXXX, FN=X, FLAGS=XXX"
Ahora bien, es importante anotar que no solamente los Access Points (AP) pueden transmitir Bacon Frames, de hecho, cualquiera puede hacerlo sin ser necesariamente un AP, es por este motivo que es importante también ver algunas de las propiedades que se incluyen en los paquetes capturados, principalmente aquellas propiedades que se encuentran ubicadas en "Fixed Parameters" y "Tagged Parameters", por ejemplo en las siguientes imágenes se enseña en primer lugar el valor del parámetro "Capability Information" que indica, entre otras si el dispositivo que ha enviado el frame es un AP y por otro lado se encuentra el valor del parámetro "SSID parameter set" que indica el identificador del AP.
En la imagen anterior, (Tagged parameters) se incluye otra información interesante que también es útil, como por ejemplo las frecuencias soportadas, el canal de ejecución actual del AP, mecanismo de autenticación, etc.
Ahora bien, todos los dispositivos inalámbricos tienen la capacidad de anunciar su presencia a otros dispositivos que se encuentran cerca, es decir, todos los dispositivos tienen (teóricamente) la capacidad de enviar Beacon Frames, evidentemente la tarjeta de red inalámbrica y el driver utilizado para controlarla deben soportar esta característica para poder ser empleada, esto a efectos prácticos significa que un atacante podría inyectar sus propios Beacon Frames haciéndose pasar por un AP, evidentemente se requiere una herramienta que permita realizar este tipo de actividades, aircrack-ng puede ser útil para este fin, no obstante en esta ocasión se mencionará otra herramienta que permitirá realizar esta tarea de una forma sencilla y efectiva, se trata de MDK3, a continuación se explica como es el procedimiento de instalación y uso.
INSTALANDO Y UTILIZANDO MDK3
Se trata de una herramienta que permite realizar operaciones varias sobre paquetes y redes inalámbricas, algunas de las características soportadas son, Prueba de redes (para verificar que pueden escuchar los beacon frames del atacante), Fuerza Bruta para filtros MAC, Fuerza Bruta para SSID ocultos, Inyección de paquetes de Deautenticacion y Desasociacion, FakeAP, etc. La instalación es muy simple, solo es necesario descargar la herramienta desde No tienes permitido ver los links. Registrarse o Entrar a mi cuenta y posteriormente ejecutar el comando "make && make install" desde linea de comandos para realizar la instalación de la herramienta.
Cuando se ejecuta el comando mdk3 sin ningún argumento, se enseñan todos los mecanismos empleados por mdk3 y cada una de estas técnicas tienen un conjunto de opciones para personalizar su ejecución, en este caso concreto interesa utilizar el modo de prueba "Beacon Flood Mode" que corresponde a la opción "b", para conocer las opciones de este modo de prueba
Citar>mdk3 –help b
b – Beacon Flood Mode
Sends beacon frames to show fake APs at clients.
This can sometimes crash network scanners and even drivers!
OPTIONS:
-n <ssid>
Use SSID <ssid> instead of randomly generated ones
-f <filename>
Read SSIDs from file
-v <filename>
Read MACs and SSIDs from file. See example file!
-d
Show station as Ad-Hoc
-w
Set WEP bit (Generates encrypted networks)
-g
Show station as 54 Mbit
-t
Show station using WPA TKIP encryption
-a
Show station using WPA AES encryption
-m
Use valid accesspoint MAC from OUI database
-h
Hop to channel where AP is spoofed
This makes the test more effective against some devices/drivers
But it reduces packet rate due to channel hopping.
-c <chan>
Fake an AP on channel <chan>. If you want your card to hop on
this channel, you have to set -h option, too!
-s <pps>
Set speed in packets per second (Default: 50)
Ahora, la ejecución del comando con la opción "b" podría incluir un SSID "falso" que identifique cada uno de los Beacon Frames enviados por broadcast a los clientes cercanos, para ello se ejecuta el siguiente comando
Citar>mdk3 mon0 b -n REMEMBER
Current MAC: C6:69:73:51:FF:4A on Channel 2 with SSID: REMEMBER
Current MAC: D8:35:E8:D4:66:82 on Channel 1 with SSID: REMEMBER
Current MAC: FA:5A:D8:B0:B5:DB on Channel 14 with SSID: REMEMBER
Como puede verse, se ejecuta de forma repetida el envío de Beacon Frames sobre distintos canales (aquí "mon0" corresponde a la interfaz en modo monitor), posteriormente cualquier cliente reconocerá dichos Beacon Frames y posiblemente los identificará como emisiones provenientes de un AP que se encuentra cerca.
Siguiendo los mismos pasos indicados anteriormente, se intenta realizar una captura de paquetes utilizando wireshark, se podrá ver que algunos de los paquetes capturados tienen en la columna "Info" un valor similar al siguiente "Beacon frame, SN=0, FN=0, Flags=........, BI=100, SSID="REMEMBER" posteriormente si se consultan los campos "Capability Information" y "SSID parameter set" (tal como se ha enseñado en las imágenes que se encuentran en párrafos anteriores) el paquete capturado tiene la apariencia de un AP.
MECANISMO DEAUTENTICACION Y ASOCIACION DE UN CLIENTE Y UN AP.
Cuando un cliente se autentica y se asocia a un AP (realiza una conexión completa) se llevan a cabo una serie de pasos y existe un intercambio de paquetes entre ambas partes que les permiten negociar una conexión entre ambos e intercambiar, posteriormente paquetes de datos.
El paso inicial lo toma el cliente y consiste en el envío de paquetes "Probe Request" que son del tipo Broadcast a cualquier AP que se encuentre cerca, la finalidad de estos paquetes es la de localizar y obtener los SSID de los AP disponibles, el cliente se mantendrá enviando este tipo de frames con la finalidad de obtener respuestas de los AP disponibles, estos a su vez responden con paquetes del tipo "Probe Response" que contienen información sobre el AP, posteriormente el cliente inicia todo el proceso de autenticación y asociación con el AP. Todo el proceso se resume en el siguiente intercambio de paquetes:
"Probe Request" → "Probe Response" → "Authentication Request" → "Authentication Response" → "Association Request" → "Association Response" → "NULL Function (No Data)" → "Disassociate".
El primer paquete "Probe Request" que el cliente envía a todos los AP cercanos, es una petición del tipo "Soy un cliente nuevo y busco AP's en el área, enviadme vuestros SSID" el siguiente paquete que es el "Probe Response" es el de respuesta de dicha petición, donde cada uno de los AP responde con su SSID (excepto aquellos que tienen SSID oculto, se verá más adelante en próximas entradas) además de esto, también incluye información relacionada con el mecanismo de autenticación y parámetros de seguridad existentes en el AP antes de comenzar la interacción con este. Posteriormente el cliente envía un paquete de "Probe Request" a un SSID concreto (el primero ha sido broadcast a todos los AP disponibles) e inicia el proceso de autenticación sobre dicho AP que ha respondido a la petición, dependiendo del mecanismo de autenticación implementado en dicho AP, estos paquetes podrán ser trazables o no, en cualquier caso, el siguiente paso es el intercambio de una serie de paquetes del tipo "Authentication" (Request por parte del cliente y Response por parte del AP) que intentan determinar si el cliente tiene autorización para asociarse con el AP, una vez este proceso ha concluido correctamente, el cliente envía una petición "Association Request" al AP para que este establezca la conexión con el cliente y le asigne una dirección IP valida (típicamente por medio de un servidor DHCP), el AP envía un paquete "Association Response" el cual contiene la respuesta exitosa o fallida de la asociación del cliente con el AP, esta respuesta se encuentra contenida en los "Fixed Parameters" con los campos "Status Code" y "Association ID" cuando el procedimiento de asociación finaliza correctamente estos campos tienen el valor de "Successful 0×0000" y "0×0001" respectivamente. Ahora con un cliente conectado con el AP, comienza el proceso de intercambio de paquetes de datos entre el cliente y el AP, por ejemplo, cuando un cliente solicita una página en internet o intenta intercambiar paquetes con otra máquina conectada en el segmento de red. Finalmente, el proceso de Des-asociación, es iniciado por el cliente y se lleva a cabo cuando este desea finalizar la interacción con el AP, en este caso el AP "des-asocia" el cliente terminando la conexión existente.
El proceso completo se entiende mejor con un ejemplo practico, para ello se pueden seguir los siguientes pasos
1.Iniciar un AP sin establecer mecanismo de autenticación utilizando airbase-ng
Citar>airmon-ng start wlan02.Establecer la tarjeta de red y la interfaz mon0 en el mismo canal que el AP.
>airbase-ng -N -P -c 1 -e WLAN_OPEN mon0
Citar>iwconfig wlan0 channel 1
>iwconfig mon0 channel 1
3.Iniciar wireshark e iniciar una captura activa de paquetes utilizando la interfaz monitora "mon0"
4.Ahora, para que la captura sea "limpia" se debe establecer un filtro en el que solamente se enseñen los frames cuya dirección corresponda al AP "WLAN_OPEN" y ademas es necesario filtrar también los Beacon Frames, con el fin de solamente recibir aquellos frames relacionados con el proceso de asociación de un cliente con un AP. Esto se hace como se enseña en las imágenes.
Como puede apreciarse el filtro resultante es el siguiente
Citar(wlan.addr == 4c:0f:6e:e9:7f:16) && !(wlan.fc.type_subtype == 0×05)
De esta forma, desde wireshark solamente se listarán registros de frames correspondientes al AP "WLAN_OPEN" y no se listarán sus Beacon Frames, solamente frames relacionados con la conexiones de otros clientes. Ahora cuando un cliente intenté realizar una conexión con el AP (Que no tiene ningún mecanismo de autenticación) se comenzará la serie de intercambio de paquetes indicada anteriormente, todos estos se pueden analizar desde wireshark
Como conclusión final de esta entrada, es importante anotar que realizar spoofing de Beacon frames es una tarea sencilla, la razón de esto es por que no existe cifrado de datos, todo viaja en texto claro y por otro lado no existe un mecanismo de protección disponible contra este tipo de ataques de reconocimiento, aunque por si mismos no son demasiado dañinos, suministran información a un posible atacante de los AP que se encuentran en "su vecindad".
LOG DE MODERACION: Siempre deben ser citadas las fuentes.
No tienes permitido ver los links. Registrarse o Entrar a mi cuenta

